目录
1,联络点配置
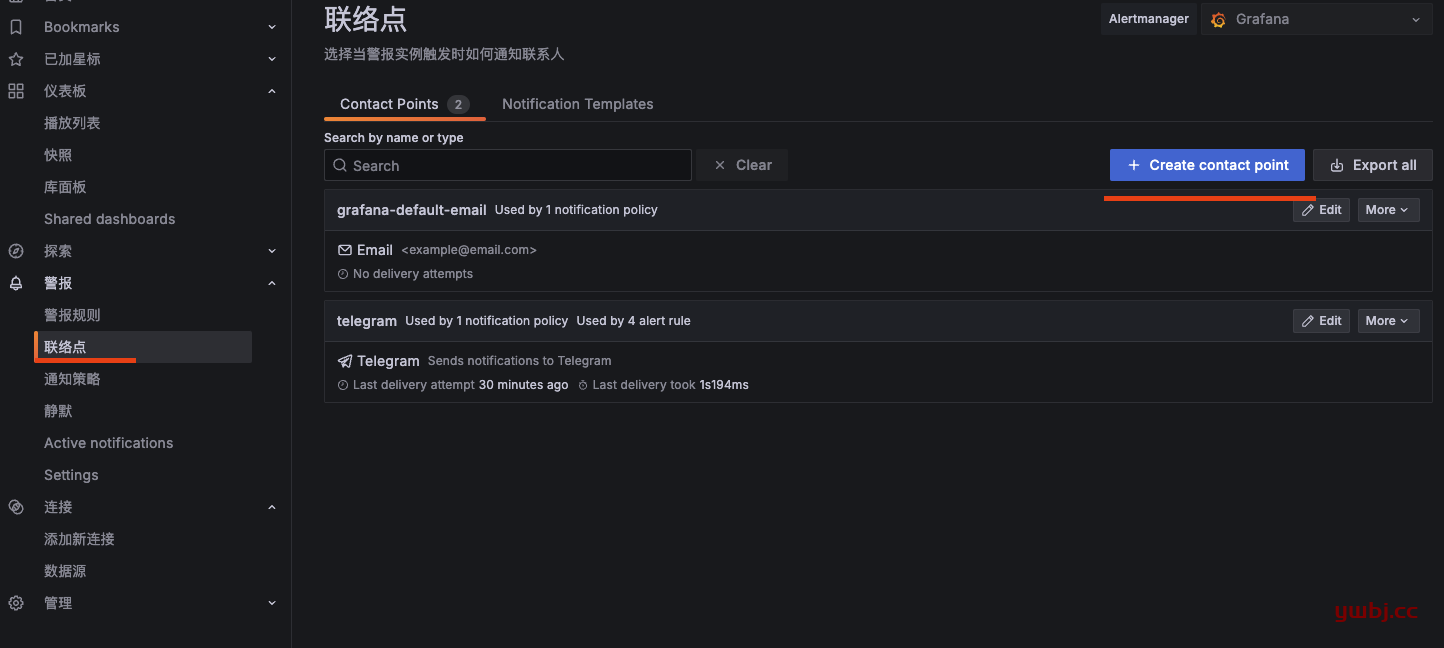
默认只有email告警,需要添加telegram告警。我已经添加telegram通知,没有的就create contact point 添加
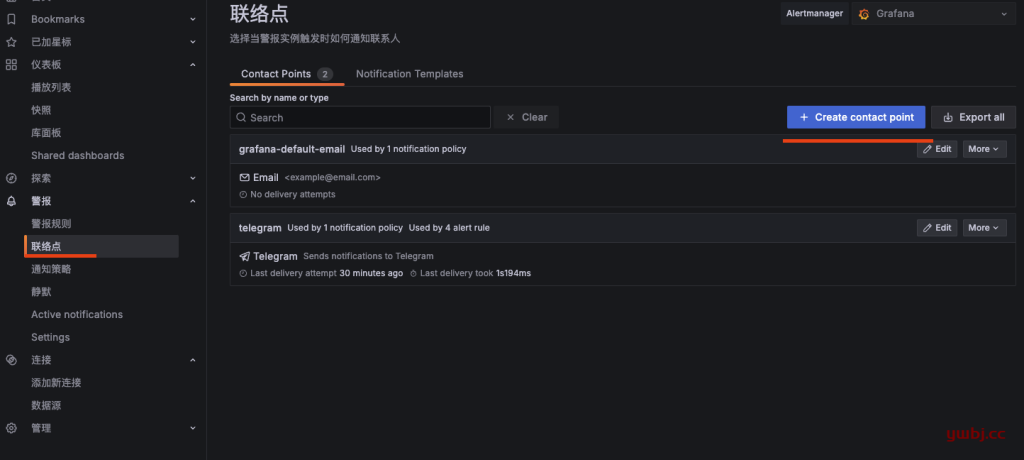
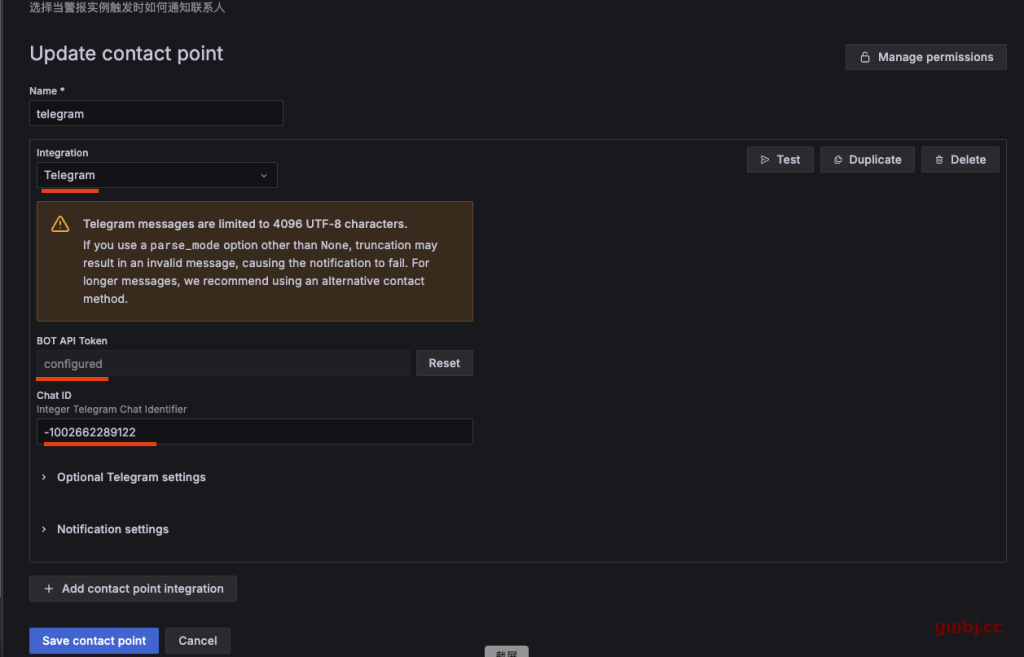
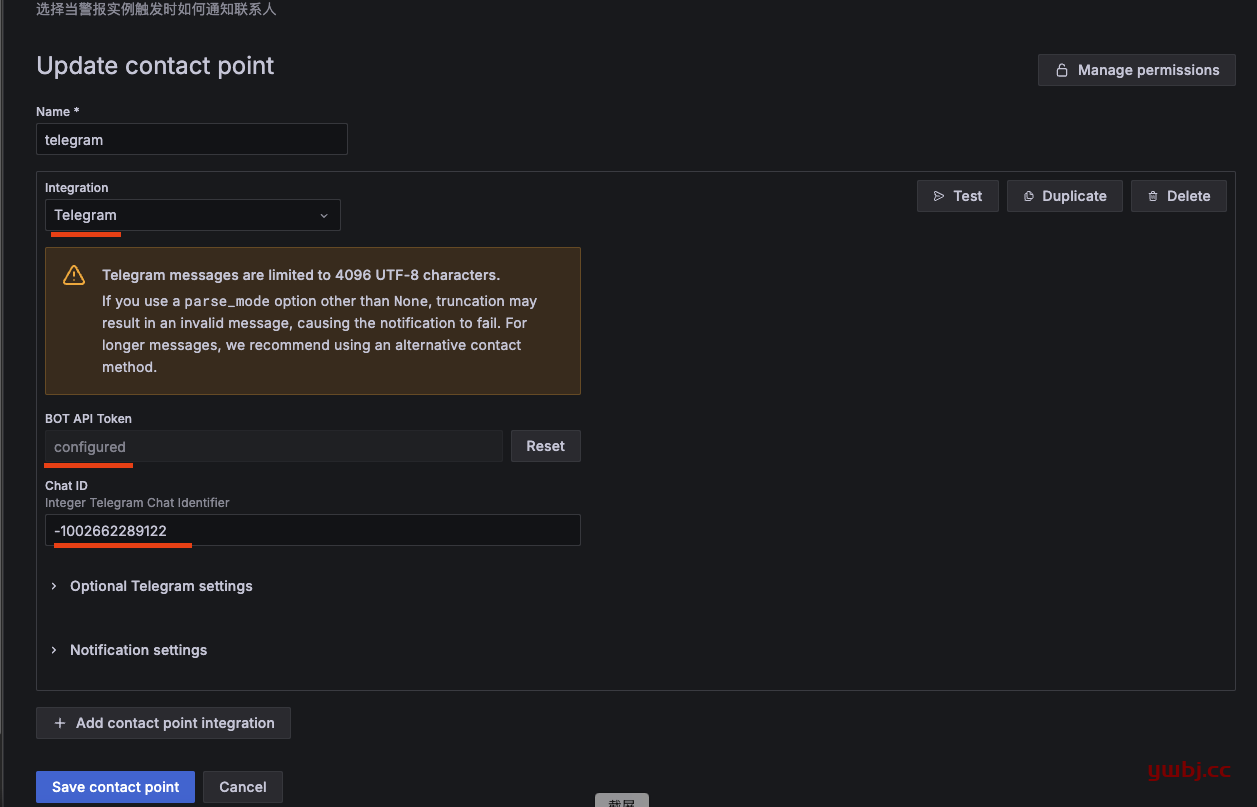
选择telegram,添加自己telegram群组的ID和token,添加完成,可以test测试是否有发送消息到群组。
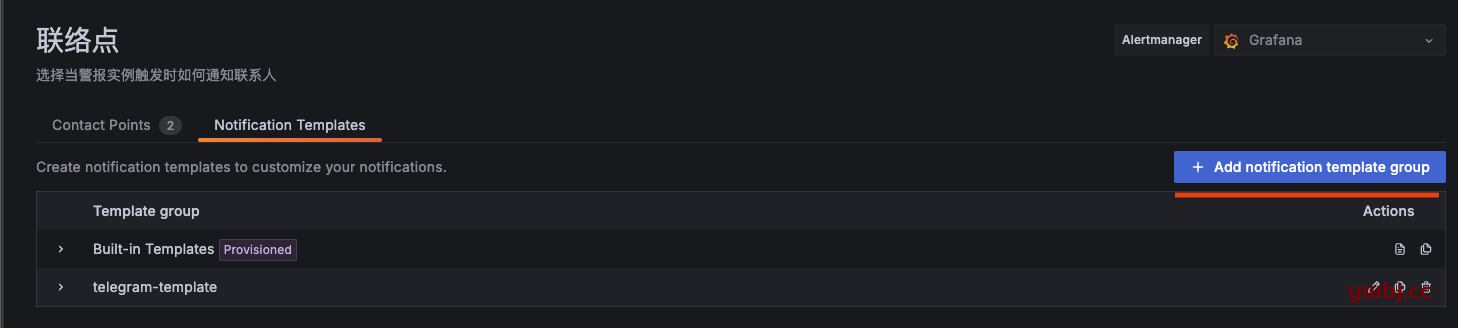
通知方式添加完成,在自己编写通知模版,notification templates >> add notification template group
模版关系到发送到群组的格式友好输入,以及数据获取方式。
语言是GO语言,如果懂GO语言,很好理解和更改,这是我的模版示例:
{{ define "telegram_message" }}
{{ $firingCount := len .Alerts.Firing }}
{{ $resolvedCount := len .Alerts.Resolved }}
{{ if gt $firingCount 0 }}
🚨 {{ $firingCount }} Alert(s) Firing 🚨
{{ range .Alerts.Firing }}{{ template "telegram_alert" . }}{{ end }}
{{ end }}
{{ if gt $resolvedCount 0 }}
✅ {{ $resolvedCount }} Alert(s) Resolved ✅
{{ range .Alerts.Resolved }}{{ template "telegram_alert" . }}{{ end }}
{{ end }}
{{ end }}
{{- define "telegram_alert" -}}
{{- if eq .Status "firing" }}🔥{{ else }}✅{{ end -}} **{{ .Labels.alertname }}**
- *Instance:* {{ .Labels.instance }}
- *Hostname:* {{ .Labels.nodename }}
- *Node job:* {{ .Labels.job }}
- *Grafana Group:* {{ .Labels.grafana_folder }}
{{- $Tag := .Labels.tag }}
{{- if eq $Tag "disk" }} {{/* Disk Space Used% Basic */}}
{{- with $size := index .Values "E" }}
- *Size:* {{ printf "%.2f" $size }} Gb
{{- end }}
{{- with $availsize := index .Values "F" }}
- *Avail Size:* {{ printf "%.2f" $availsize }} Gb
{{- end }}
{{- with $value := index .Values "A" }}
- *Disk Usage:* {{ printf "%.2f" $value }}%
{{- end }}
{{- else if eq $Tag "memory" }} {{/* Memory Basic */}}
{{- with $memsize := index .Values "A" }}
- **Memory size:** {{ printf "%.2f" $memsize }} Gb
{{- end }}
{{- with $used := index .Values "F" }}
- **Memory Avail:** {{ printf "%.2f" $used }} Gb
{{- end }}
{{- with $usage := index .Values "H" }}
- **Memory Usage:** {{ printf "%.2f" $usage }}%
{{- end }}
{{- else if eq $Tag "cpu" }} {{/* CPU% Basic */}}
{{- with $cpucore := index .Values "A" }}
- **CPU:** {{ printf "%.0f" $cpucore }}
{{- end }}
{{- with $cpuUsage := index .Values "F" }}
- **CPU Usage:** {{ printf "%.2f" $cpuUsage }}%
{{- end }}
{{- end }}
- **{{ if eq .Status "firing" }}Triggered{{ else }}Resolved{{ end }} At:** {{ if eq .Status "firing" }}{{ .StartsAt | tz "Asia/Phnom_Penh" }}{{ else }}{{ .EndsAt | tz "Asia/Phnom_Penh" }}{{ end }}
{{ "\n" }}
{{- end }}
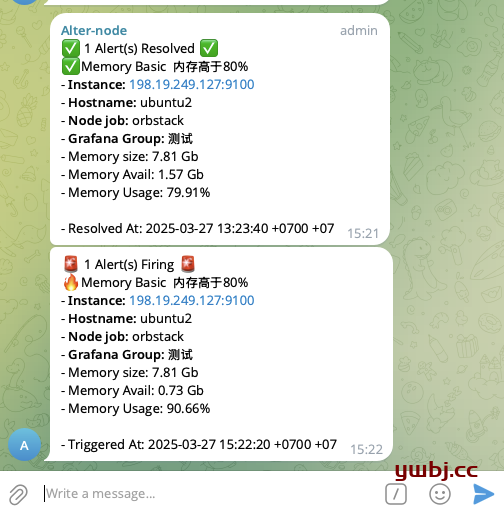
主要功能,添加 告警 和 解决 两个通知。监控指标为cpu,内存,硬盘。
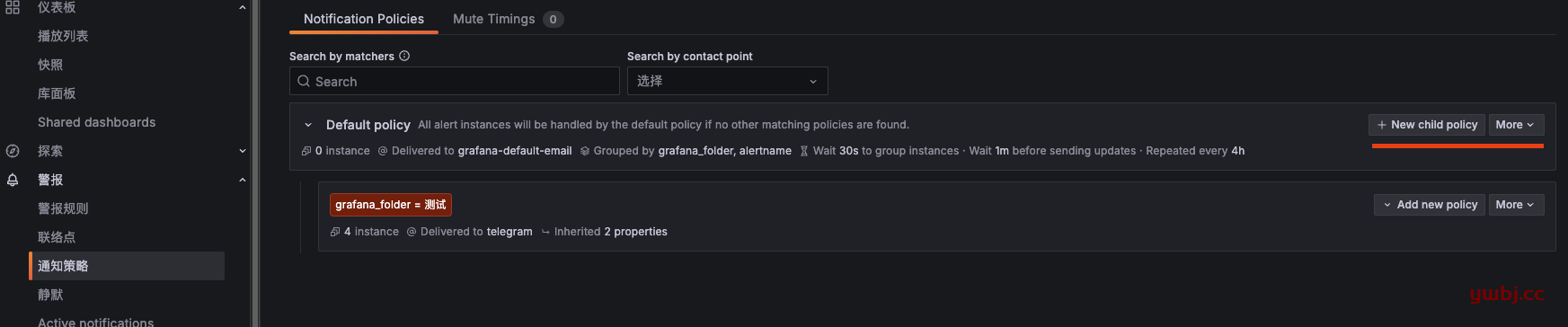
2,添加通知策略
默认的通知策略,也是通过默认的email发送的,所以需要更改。
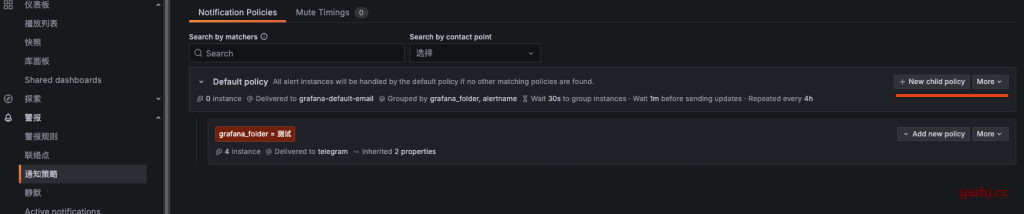
可以直接更改默认策略,在more 里面edit 选择刚才配置的联络点。当然这意味所有告警都发送到刚才到联络点。
如果有多个分组发送到不同的联络点群组,就创建子策略 >> new child policy。
如我这里仪表板有两个文件夹,只需要 “测试” 的这个文件夹发送到刚才配置的telegram群组,就需要创建子策略。
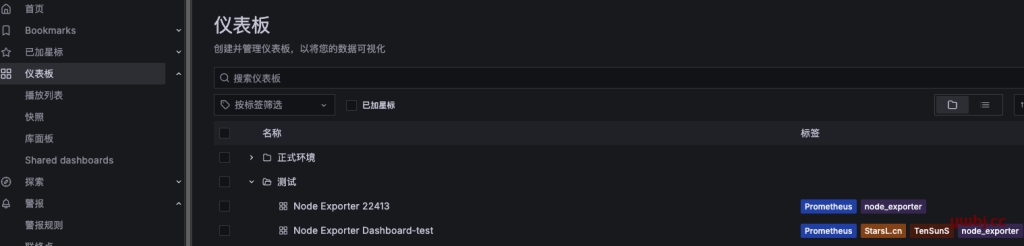
子策略如下,只需要 grafana_folder 指定文件夹即可,选择对应的 通知群组。
3,警报规则
最后配置警报规则,所有的规则都是基于仪表板模版创建,仪表板模版不一样,所以参数不一样,不能通用。
第一次接触的人感觉比较懵逼,不知道填什么,就是填数据库查询语句,这里有个简单的方法。
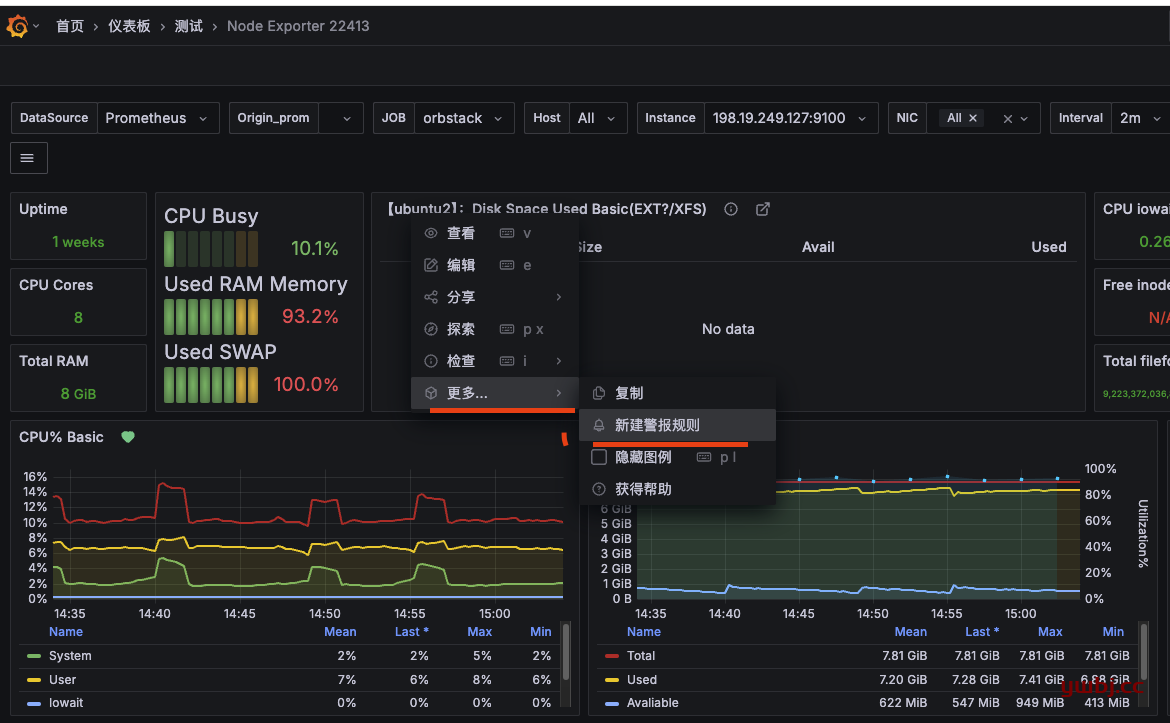
直接在需要监控的面板中,创建规则,进入就直接选择需要的规则即可。

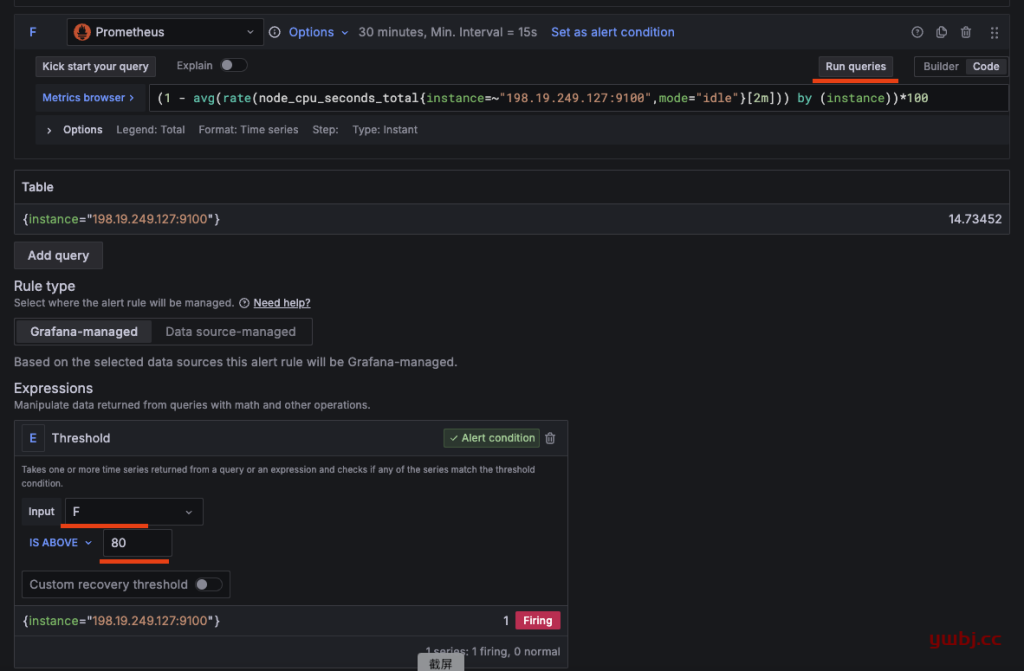
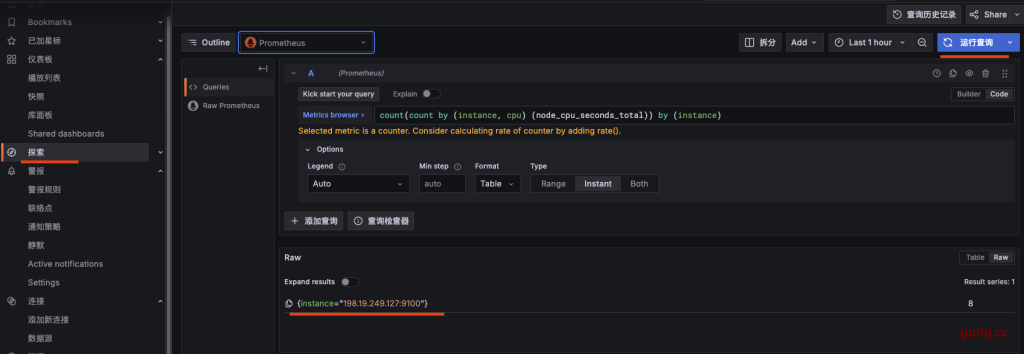
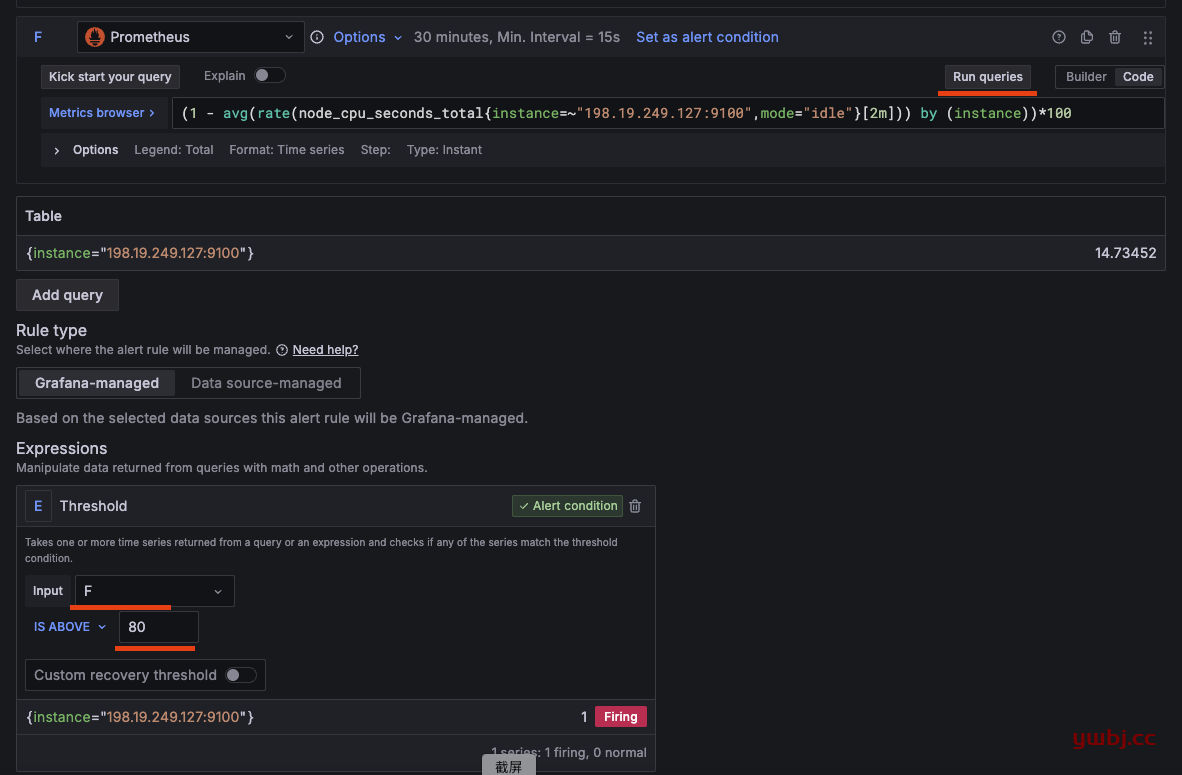
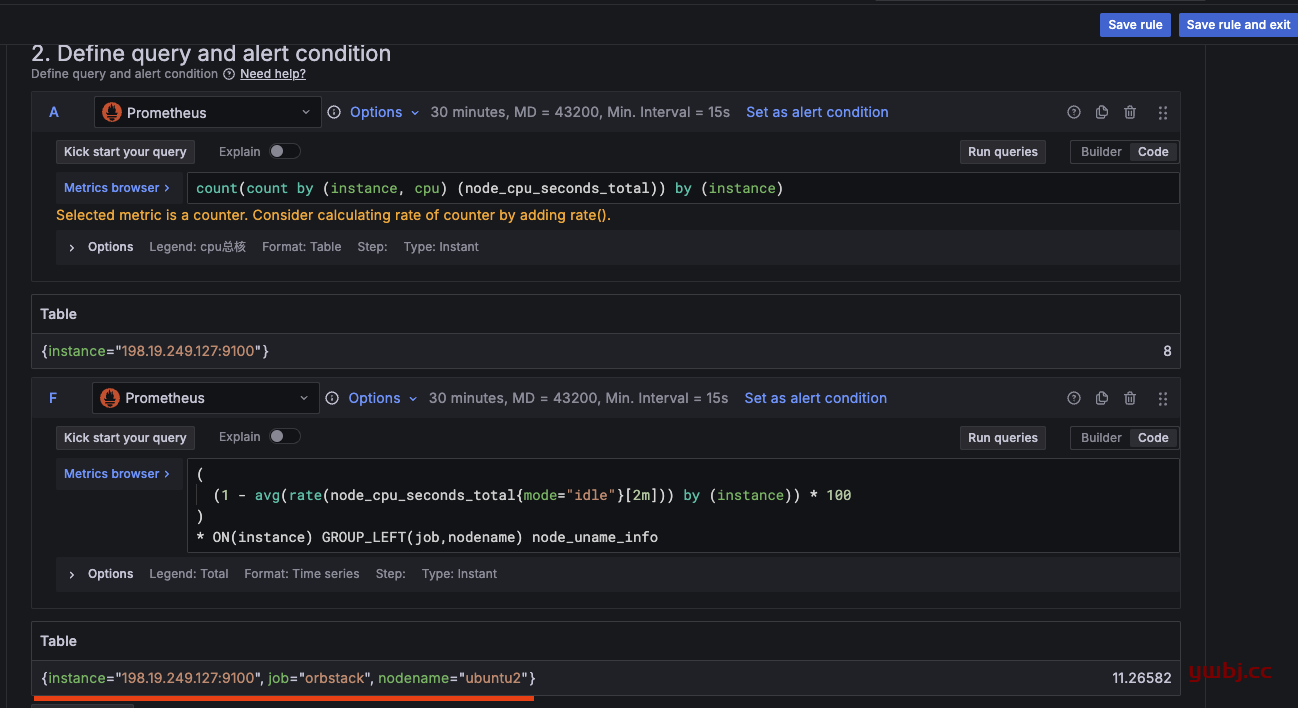
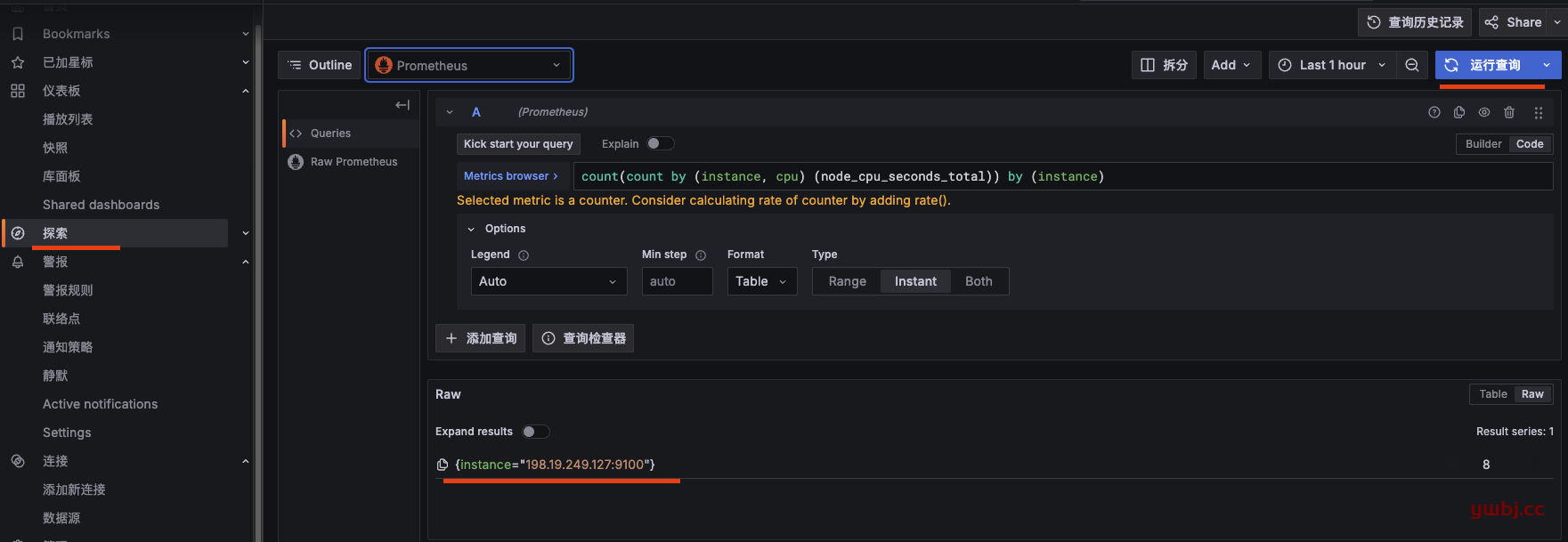
在规则中,点查询 run queries 运行查询结果,这里F 就是我需要的结果,利用率。
{instance="198.19.249.127:9100"} 14.73452
下面报警值,F 达到 80 就报警, alter condition就是已经设置此值为告警值,没有的话,就点击set as altert condition。
自定义修改规则查询语句,如果对于原来对结果数据少,可以增加查询条件,如这里F 增加了查询条件,得到更多值:
{instance="198.19.249.127:9100", job="orbstack", nodename="ubuntu2"} 11.26582
为什么要这么多值?
因为只有在查询得到的值标签,才能在notification templates 告警模版中使用,如上面的模版,我需要用到 nodename 和 job 获取监控机器的 组和主机名称。
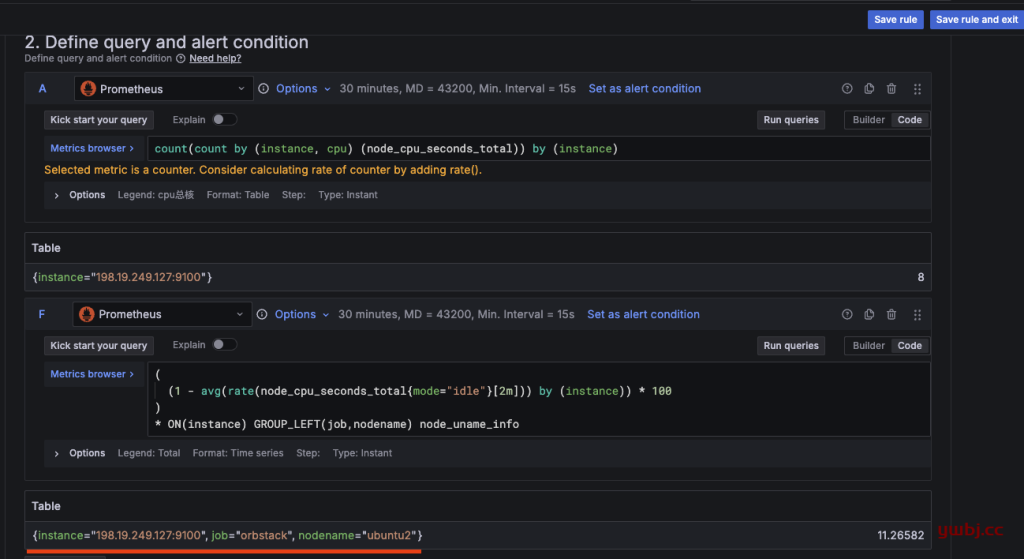
A 的值,是获取cpu 核心数,原来没有,如果不会查询语言,直接叫AI 帮你写,写完在 探索 测试查询结果就可以了。
下面选择文件夹,这里我自定义添加了一个标签 tag 对应cpu,因为上面的告警模版,我是通过调用tag 值来匹配规则告警的。
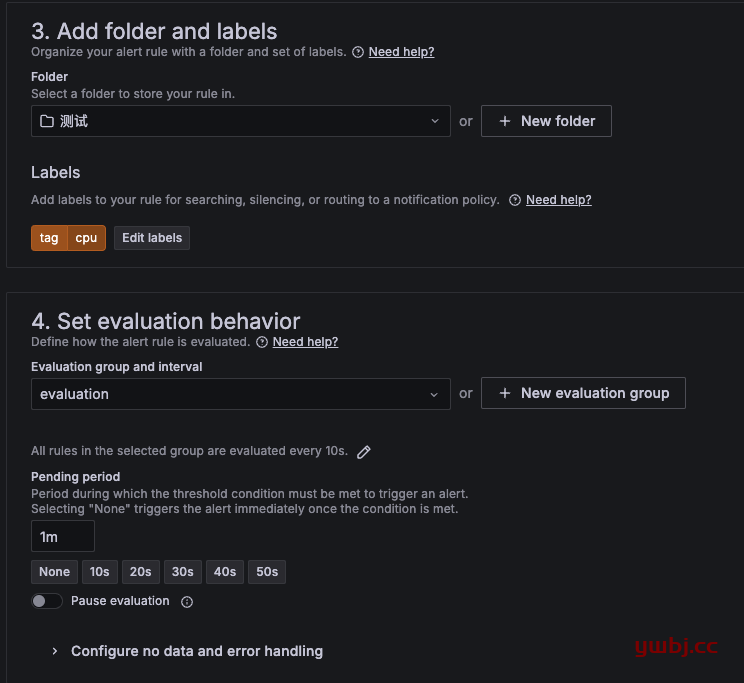
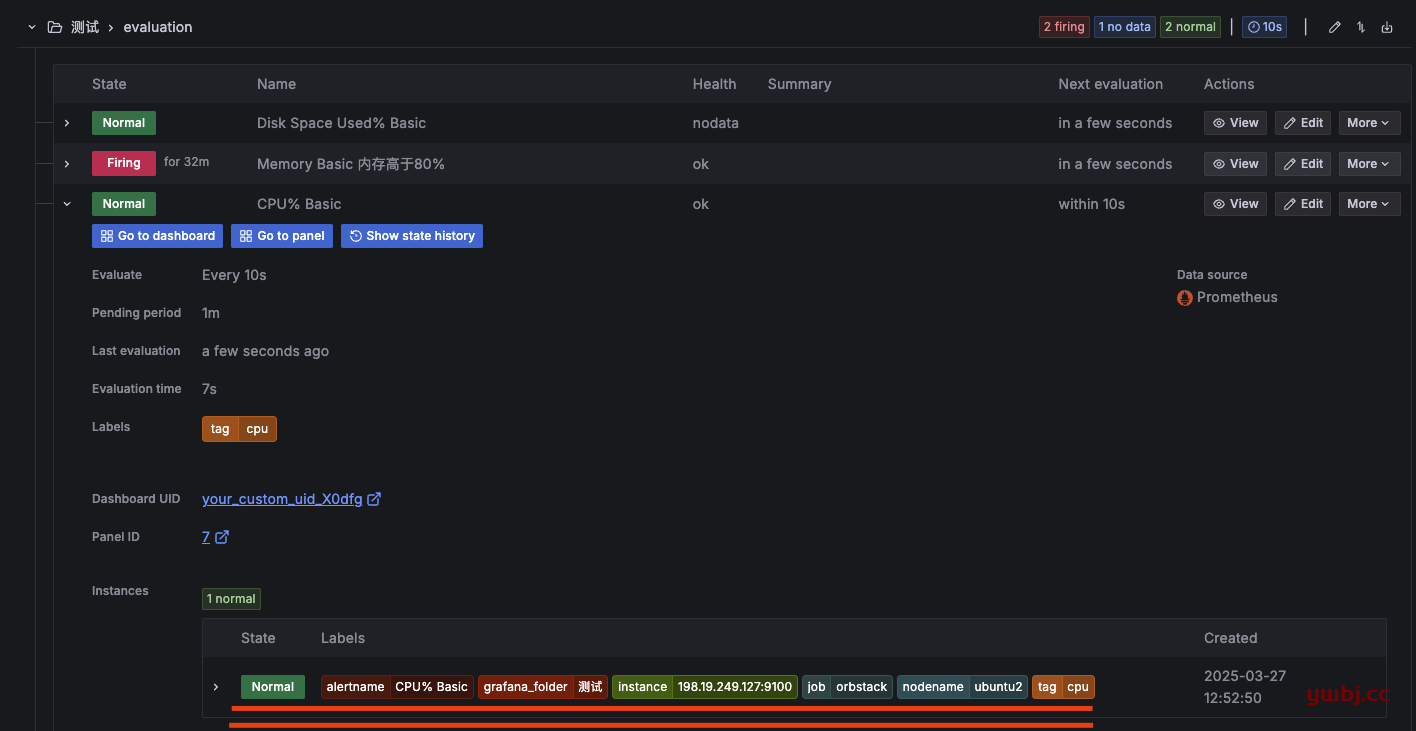
evaluation评估组,就是达到告警时,评估时间。
如这里,评估组时间10s,规则pending时间1m,cpu达到阈值80时,会在1分钟之内评估7次,7次都达到阈值触发告警通知。如果30s,就是1分钟评估3次触发。
作用其实就是预防一些瞬间值触发阈值而误报,所以多次评估。根据实际情况调整评估时间。

grafana 在11版本中,在规则中可以直接选择 告警联络点,即发送的联络群组,10版本以下没有这个选项,直接在 通知策略中配置生效。
最后选择监控的面板即可,选择cpu 面板。
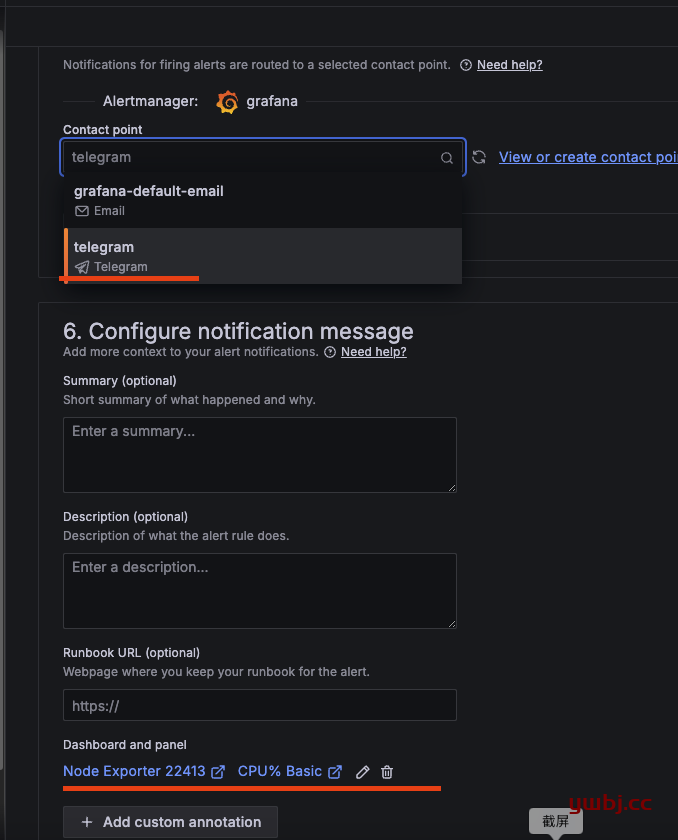
最后保存规则,就可以了,其他监控指标同理添加即可。
监控服务器是否宕机查询语句很简单,添加一条规则 up == 0 即可,0 为宕机,1为正常。
{__name__="up", instance="172.16.81.128:9100", job="VMware"} 0
{__name__="up", instance="198.19.249.12:9100", job="orbstack"} 0
4,关于标签
创建完规则后,可以看到这条规则可以用到的标签,只有这些显示的标签,才能在 告警模版 中调用获取数据生效。调用方式ex:.Labels.nodename
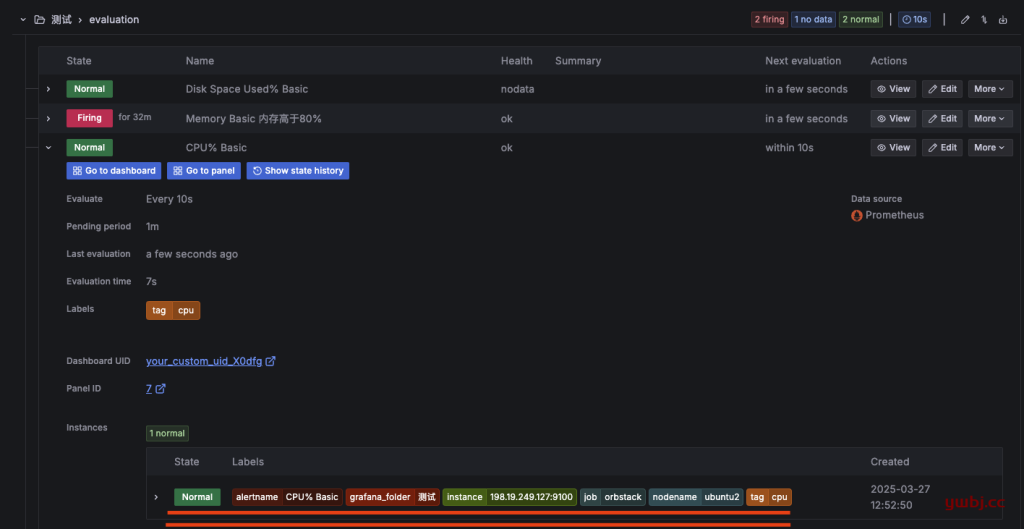
当然还有些公共标签,是所有规则可以用的,可以在官网查询公共标签。
5,静默
静默就是屏蔽,如监控有大量服务器时,由于默认的sqlite 太小,只支持单写模式,经常锁表,导致DatasourceError 报错,同时也会发送通知,如不想这类报错发送到群组,可以静默屏蔽掉。
也可以屏蔽对应的主机通知。

6,最后测试结果展示


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}