目录
一,功能描述
功能1:自动收录群或者频道信息
TG自建Bot机器人,然后可以将机器人Bot 拉入群或频道,然后自动收集实时信息,生成信息链接,并和文本信息采集到数据库。
功能2:私聊搜索功能
私聊时,Bot通过用户输入的关键词,自动在数据库模糊搜索文本信息,并将缩略文本已超链接的方式反馈给用户
备注:
以下代码在TG api版本13.15下运行开发,默认安装的未20以上版本,可能需要自行更改相关参数。
安装13.15版本:
pip install python-telegram-bot==13.15
查询api 库的命令:
pip show python-telegram-bot
这里默认采用最简单最小的sqlite3数据库,如果数据量很大,可以自行更改为mysql或其他数据库。
二,收录群或者频道信息功能
1,数据库表说明
6个字段。
- id:主键唯一,自增,防止采集收据冲突
- message_id:信息链接的id。
- chat_id:群组或者频道id。
- message_type:识别信息类型为视频,图文,还是纯文字。
- link:通过采集到的群组名或者频道名和message_id组成链接。
- content:信息文字相关信息。
2,其他方法功能说明
- 群组和频道的消息处理逻辑不同,所以通过检查 update.message 和 update.channel_post:分别处理群组消息和频道消息。
- 优化脚本以去除 content 中的空格、换行符以及表情包和特殊符号,可以使用 Python 的 strip() 方法和 replace() 方法去掉两端空格、换行符以及中间的多余空格。
- 可以使用正则表达式来匹配和去除特殊符号和表情包。re.sub(r'[^\w\s]’, ”, content) 去除所有非字母、非数字、非空格的字符(包括表情包和特殊符号)
\w:匹配字母、数字、下划线。
\s:匹配空格。
^:表示取反,匹配非字母、非数字、非空格的字符。
def create_table():
conn = sqlite3.connect(DATABASE)
c = conn.cursor()
# 添加自增的主键 id 列
c.execute('''CREATE TABLE IF NOT EXISTS messages
(id INTEGER PRIMARY KEY AUTOINCREMENT,
message_id INTEGER,
chat_id INTEGER,
message_type TEXT,
link TEXT,
content TEXT)''')
conn.commit()
conn.close()
3,完整代码展示
import re
import logging
import sqlite3
from telegram import Update, ParseMode
from telegram.ext import Updater, CommandHandler, MessageHandler, Filters, CallbackContext
from telegram.utils.helpers import escape_markdown
# 配置日志
logging.basicConfig(format='%(asctime)s - %(name)s - %(levelname)s - %(message)s', level=logging.INFO)
logger = logging.getLogger(__name__)
# 数据库设置
DATABASE = 'messages.db'
def create_table():
conn = sqlite3.connect(DATABASE)
c = conn.cursor()
# 添加自增的主键 id 列
c.execute('''CREATE TABLE IF NOT EXISTS messages
(id INTEGER PRIMARY KEY AUTOINCREMENT,
message_id INTEGER,
chat_id INTEGER,
message_type TEXT,
link TEXT,
content TEXT)''')
conn.commit()
conn.close()
def clean_content(content):
# 去除空格和换行符
content = content.strip().replace('\n', ' ').replace('\r', '')
# 使用正则表达式去除表情包和特殊符号
# 这里只是示例,可以根据需要进行调整,去除非标准字符
content = re.sub(r'[^\w\s]', '', content) # 只保留字母、数字和下划线
return content
def save_message(message_id, chat_id, message_type, link, content):
try:
conn = sqlite3.connect(DATABASE)
c = conn.cursor()
# 清理 content
if content:
content = clean_content(content)
# 插入数据时,数据库会自动生成自增的 id
c.execute("""
INSERT INTO messages
(message_id, chat_id, message_type, link, content)
VALUES (?, ?, ?, ?, ?)
""", (message_id, chat_id, message_type, link, content))
conn.commit()
conn.close()
logger.info(f"Message saved to database: {link}")
except sqlite3.Error as e:
logger.error(f"Database error: {e}")
except Exception as e:
logger.error(f"Error in save_message: {e}")
def start(update: Update, context: CallbackContext):
update.message.reply_text('Bot is now monitoring messages!')
def handle_message(update: Update, context: CallbackContext):
try:
# 判断消息类型
if update.message:
message = update.message
elif update.channel_post:
message = update.channel_post
else:
logger.error("No message or channel_post found in update.")
return
# 确保 message_id 存在
if message.message_id is None:
logger.error("Message ID is missing in message or channel_post.")
return
chat_id = message.chat_id
message_id = message.message_id
# 判断是否为群组或频道的文本消息
text = message.text if message.text else message.caption
# 判断消息类型并生成链接
if message.photo:
message_type = 'photo'
link = f"https://t.me/{message.chat.username}/{message_id}"
elif message.video:
message_type = 'video'
link = f"https://t.me/{message.chat.username}/{message_id}"
elif text:
message_type = 'text'
link = f"https://t.me/{message.chat.username}/{message_id}"
else:
logger.error("Unknown message type, unable to process.")
return
# 保存消息
print(message_id, chat_id, message_type, link, text)
save_message(message_id, chat_id, message_type, link, text)
logger.info(f"Saved message: {link}")
except Exception as e:
logger.error(f"Error handling message: {e}")
def main():
create_table()
updater = Updater("54874123123:AAGibU......", use_context=True)
dp = updater.dispatcher
dp.add_handler(CommandHandler("start", start))
dp.add_handler(MessageHandler(Filters.all & ~Filters.command, handle_message))
updater.start_polling()
updater.idle()
if __name__ == '__main__':
main()
将以下机器人token换成自己的即可。
updater = Updater("54874123123:AAGibU......", use_context=True)
4,运行测试结果
注:只能实时监控到公开群组和频道,频道机器人为admin权限
将机器人拉入群组和频道,发送信息测试
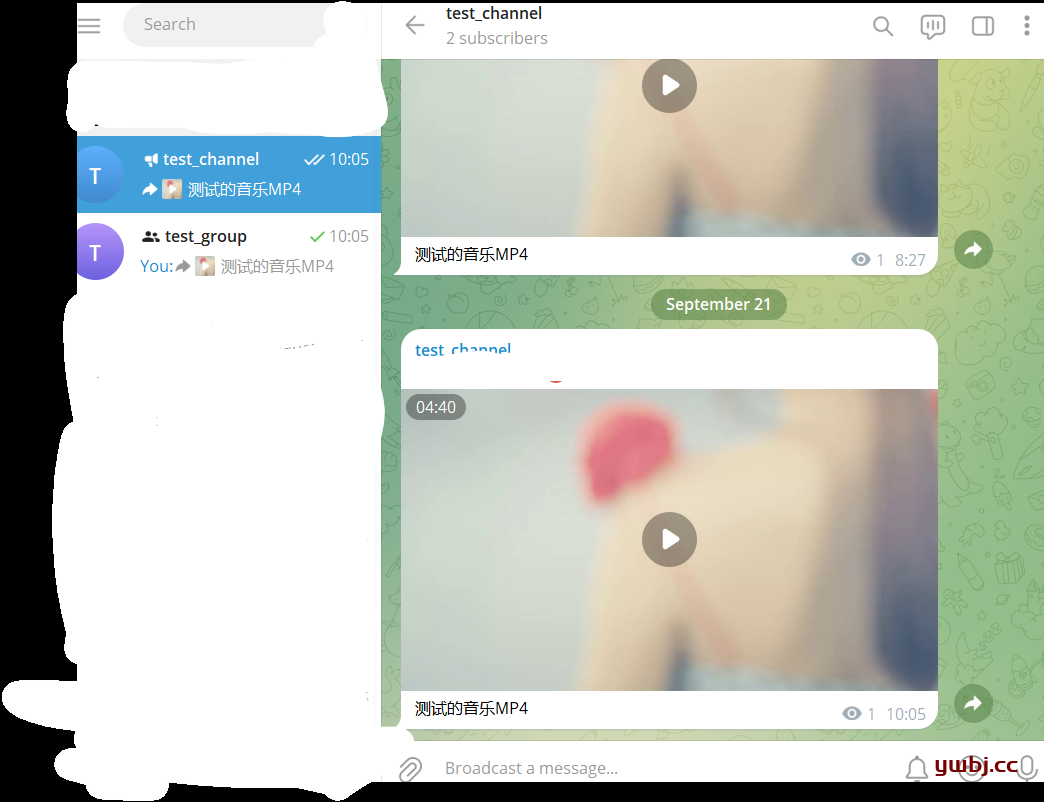{kind=link}

后台服务器显示内容

数据库messages.db查看
{kind=link}

数据插入成功。
三,私聊搜索功能实现
1,方法说明
- search_messages 函数负责从 messages.db 中模糊搜索关键词匹配的 content。
- handle_message 函数会处理用户的私聊消息,调用 search_messages 函数进行数据库查询,并将结果展示给用户。如果有多条结果,将会按列表形式返回。
- 返回的链接和内容将会用 Markdown 格式生成超链接。
- 使用 Filters.text & ~Filters.group 过滤器确保只处理私聊信息。
- 缩略内容生成:通过 get_snippet 函数,找到关键词在 content 中的位置,并从关键词前后截取一定长度的字符串(默认 15 个字符左右),只显示包含关键词的片段,而不显示完整内容。
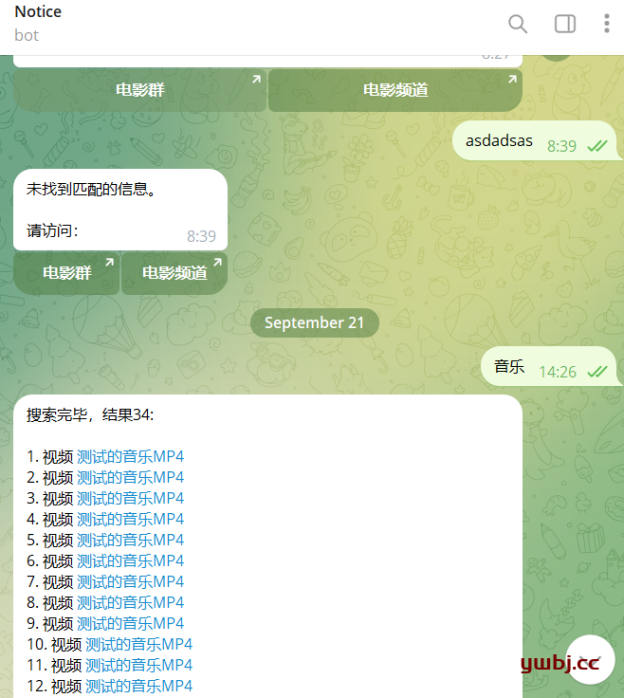
- 显示结果数量:在搜索结果的开头添加一行,显示“搜索完毕,结果X”。
- 消息类型标注:每条结果前根据 message_type 添加标注:“视频”“图文”“文字”。
- 分页显示:每次搜索只显示最多 20 条结果,通过“下一页”和“上一页”按钮进行分页查看。
- 分页按钮:当搜索结果超过 20 条时,显示“上一页”和“下一页”按钮。
- 跳转链接按钮:第二排添加了两个按钮,分别跳转到电影群和电影频道的 Telegram 链接。
2,代码
import sqlite3
from telegram import Update, InlineKeyboardButton, InlineKeyboardMarkup
from telegram.ext import Updater, CallbackQueryHandler, MessageHandler, Filters, CallbackContext
# 每页显示的结果数量
RESULTS_PER_PAGE = 20
# 数据库查询函数
def search_messages(keyword):
conn = sqlite3.connect('messages.db')
cursor = conn.cursor()
# 模糊搜索content
query = "SELECT link, content, message_type FROM messages WHERE content LIKE ?"
cursor.execute(query, ('%' + keyword + '%',))
results = cursor.fetchall()
conn.close()
return results
# 清理空格和换行符的函数
def clean_text(text):
import re
return re.sub(r'\s+', '', text) # 去除所有空格和换行符
# 截取包含关键词的缩略内容
def get_snippet(content, keyword, snippet_length=15):
cleaned_content = clean_text(content) # 清理内容
keyword_start = cleaned_content.lower().find(keyword.lower()) # 找到关键词的位置
if keyword_start == -1: # 关键词未找到
return cleaned_content[:snippet_length] # 返回前 snippet_length 个字符
# 计算关键词前后应该显示的字符数
start = max(0, keyword_start - snippet_length // 2)
end = min(len(cleaned_content), keyword_start + len(keyword) + snippet_length // 2)
# 如果开头不在第一位,添加省略号
snippet = ('...' if start > 0 else '') + cleaned_content[start:end] + ('...' if end < len(cleaned_content) else '')
return snippet
# 根据message_type返回对应类型标注
def get_message_type_label(message_type):
if message_type == "video":
return "视频"
elif message_type == "image":
return "图文"
else:
return "文字"
# 生成分页的回复内容和按钮
def get_paginated_results(results, page, keyword):
start_idx = page * RESULTS_PER_PAGE
end_idx = start_idx + RESULTS_PER_PAGE
paginated_results = results[start_idx:end_idx]
response = f"搜索完毕,结果{len(results)}:\n\n"
for idx, (link, content, message_type) in enumerate(paginated_results, start=start_idx + 1):
snippet = get_snippet(content, keyword)
type_label = get_message_type_label(message_type)
response += f"{idx}. [{type_label}] [{snippet}]({link})\n"
# 创建分页按钮
keyboard = []
if len(results) > RESULTS_PER_PAGE:
nav_buttons = []
if page > 0:
nav_buttons.append(InlineKeyboardButton("首页", callback_data=f"first_page:{keyword}:0"))
nav_buttons.append(InlineKeyboardButton("上一页", callback_data=f"prev_page:{keyword}:{page-1}"))
if end_idx < len(results):
nav_buttons.append(InlineKeyboardButton("下一页", callback_data=f"next_page:{keyword}:{page+1}"))
nav_buttons.append(InlineKeyboardButton("尾页", callback_data=f"last_page:{keyword}:{(len(results) // RESULTS_PER_PAGE)}"))
keyboard.append(nav_buttons)
# 添加跳转链接按钮
keyboard.append([
InlineKeyboardButton("电影群", url="https://t.me/test_groupb..."),
InlineKeyboardButton("电影频道", url="https://t.me/testforchann....")
])
reply_markup = InlineKeyboardMarkup(keyboard)
return response, reply_markup
# 处理用户私聊消息
def handle_message(update: Update, context: CallbackContext):
user_message = update.message.text.strip()
chat_id = update.message.chat_id
results = search_messages(user_message)
if results:
response, reply_markup = get_paginated_results(results, page=0, keyword=user_message)
update.message.reply_text(response, parse_mode='Markdown', reply_markup=reply_markup)
else:
response = "未找到匹配的信息。"
# 即使没有信息也显示群和频道的按钮
response += "\n\n请访问:"
reply_markup = InlineKeyboardMarkup([
[InlineKeyboardButton("电影群", url="https://t.me/movie....."),
InlineKeyboardButton("电影频道", url="https://t.me/movie.....")]
])
update.message.reply_text(response, reply_markup=reply_markup)
# 处理分页按钮回调
def handle_pagination(update: Update, context: CallbackContext):
query = update.callback_query
action, keyword, page = query.data.split(":")
page = int(page)
results = search_messages(keyword)
if action == 'first_page':
page = 0
elif action == 'last_page':
page = len(results) // RESULTS_PER_PAGE
response, reply_markup = get_paginated_results(results, page, keyword)
query.edit_message_text(text=response, parse_mode='Markdown', reply_markup=reply_markup)
def main():
# 初始化Telegram机器人
updater = Updater("5487418237:AAG.....", use_context=True)
dp = updater.dispatcher
# 注册消息处理器,只处理私聊中的文本消息
dp.add_handler(MessageHandler(Filters.text & ~Filters.group, handle_message))
# 注册回调按钮处理器
dp.add_handler(CallbackQueryHandler(handle_pagination, pattern=r'(prev_page|next_page|first_page|last_page):'))
# 启动机器人
updater.start_polling()
updater.idle()
if __name__ == '__main__':
main()
以上将 需要跳转的群或者频道链接换成自己的,还有机器人token。
InlineKeyboardButton("电影群", url="https://t.me/test_groupb..."),
InlineKeyboardButton("电影频道", url="https://t.me/testforchann....")
3,运行测试结果
私聊机器人即可

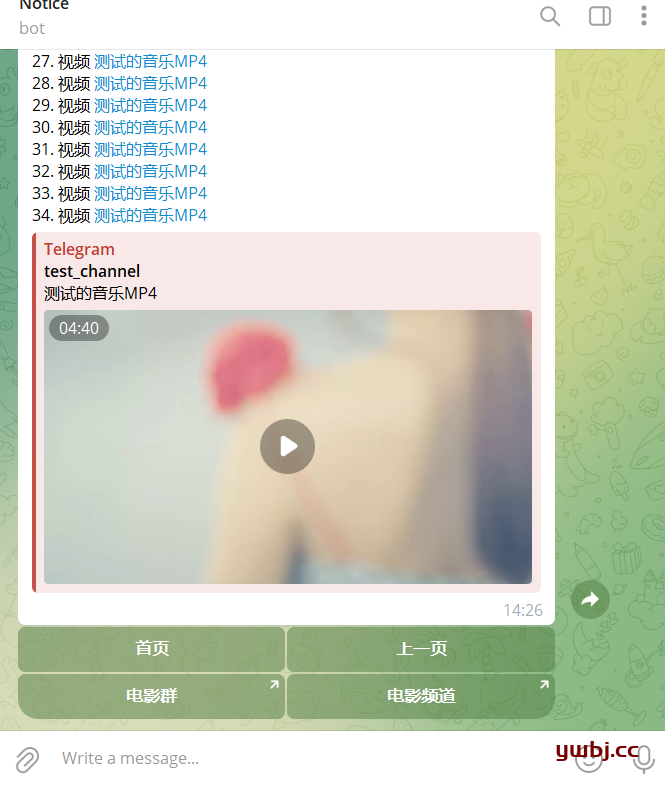
运行完成,没问题,点击文字自动跳到相关群组或者频道。
四,合并机器人功能
将上面两个功能,合并成一个脚本,同时运行。
注:机器人只有实际监控的信息的功能,并不能收录以前的历史记录。所以后面也用其他的脚本将导出的JSON历史记录导入数据库即可。导入脚本可参考最后……
合成后完整的脚本代码为:
感谢分享, 正在做一个搜索机器人,直接抄大佬的代码改了一下, 省了不少力气
可不可以帮我也做一个,有偿的