单点登录平台Casdoor搭建与使用,集成gitlab同步创建删除账号 一,简介 一般来说,公司有很多系统使用,为了实现统一的用户名管理和登录所有系统(如 GitLab、Harbor 等),并在员工离职时只需删除一个主账号即可实现权限清除,可以采用 单点登录 (SSO) 和 集中式身份认证 系统。以下工具都可使用。 Keycloak(开源,功能强大且易于部署)Okta/Auth0(商业化解决方案,支持更多高级功能)LDAP(轻量级目录访问协议,可搭配 FreeIPA) [……] 继续阅读»»»
python脚本,通过facebook官方API,每天自动在Facebook公共主页发帖 一,简介 基本功能实现,每天自动在公共主页,发布ywtv.live电影网站最新图文帖子,同时在帖子下发送评论链接。电影更新内容,在数据库中获取更新信息,下载图片,然后通过脚本发送至公共主页。 准备工作,facebook创建公共主页,https://www.facebook.com/profile.php?id=61567617441502 登录https://developers.facebook [……] 继续阅读»»»
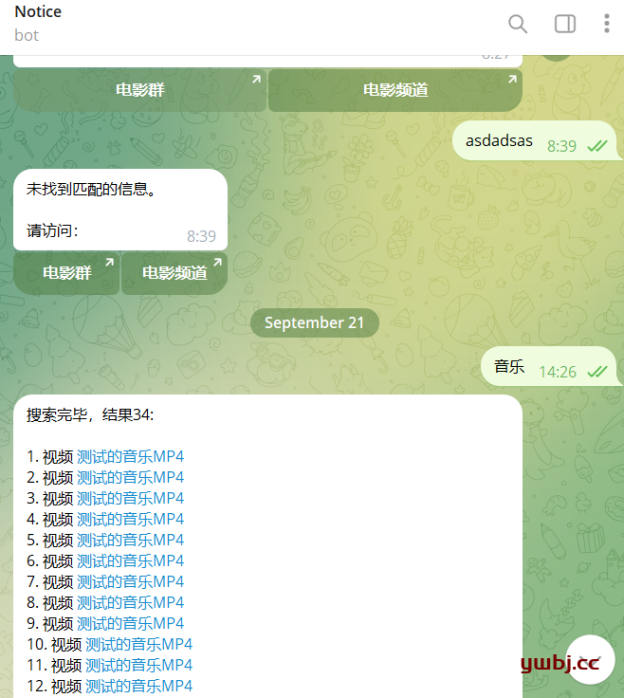
python脚本,telegram机器人Bot自动收集频道和群组信息,并实现机器人Bot搜索跳转功能 一,功能描述 功能1:自动收录群或者频道信息 TG自建Bot机器人,然后可以将机器人Bot 拉入群或频道,然后自动收集实时信息,生成信息链接,并和文本信息采集到数据库。 功能2:私聊搜索功能 私聊时,Bot通过用户输入的关键词,自动在数据库模糊搜索文本信息,并将缩略文本已超链接的方式反馈给用户 备注: 以下代码在TG api版本13.15下运行开发,默认安装的未20以上版本,可能需要自行更改相关参 [……] 继续阅读»»»
python小脚本,实时监测服务器是否宕机状态,并发送到指定Telegram群组 一,前言 众所周知,市面上监控软件很多,有Zabbix,Prometheus等,但对于相对简单的功能,需要第一时间发现问题,如服务器宕机,zabbix和Prometheus都需要等几分钟才会报警。 想到最原始的方法,也是最简单的方法,就是ping 服务器,ping断开就是宕机。所以用一个小脚本即可。 二,脚本内容 1,脚本说明: 2,脚本内容 三,脚本运行测试 原脚本由于是持续运行,所以是死循环, [……] 继续阅读»»»
python脚本,通过浏览器多开WhatsApp应用程序 1:前言 WhatsApp作为微软的开发的通讯工具,在微软的windows下基本做不到多开了。以前旧方式都已经不可使用了,或者使用第三方工具多开,但是费用也比较高。但是WhatsApp可以页面登录,所以可以使用浏览器多开,所以想到用脚本多开浏览器即可。 (文章最后提供完整代码和打包成的exe直接运行程序) 2:效果展示 直接运行脚本,或者在windows运行打包好的exe运行文件。(开发可以用脚本 [……] 继续阅读»»»
python脚本,备份获取Telegram 所有群组聊天记录、下载保存文件 前言,功能介绍 脚本功能,可在服务器设置定时任务,运行脚本。 1:生成html文件,提供css和js文件,方便阅读。 2:每次运行,单独生成以 “output-月-日-时” 名称的文件夹,下载信息在此文件夹。 3:图片和视频正常显示在聊天记录中,其他文件自行下载文件夹中,聊天记录可点击超链接直接打开。 4:默认备份24小时之内的记录,没有产生信息的群组不导出备份。需要更改时 [……] 继续阅读»»»
python爬虫之Scrapy框架,基本介绍使用以及用框架下载图片案例 一、Scrapy框架简介 Scrapy是:由Python语言开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据,只需要实现少量的代码,就能够快速的抓取。 Scrapy使用了Twisted异步网络框架来处理网络通信,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活地实现各种需求。 Scrapy可以应用在包括数据挖掘、信息处 [……] 继续阅读»»»
Python爬虫伪装,请求头User-Agent池,和代理IP池搭建使用 一、前言 在使用爬虫的时候,很多网站都有一定的反爬措施,甚至在爬取大量的数据或者频繁地访问该网站多次时还可能面临ip被禁,所以这个时候我们通常就可以找一些代理ip,和不用的浏览器来继续爬虫测试。下面就开始来简单地介绍一下User-Agent池和免费代理ip池。 二、User-Agent池 User-Agent 就是用户代理,又叫报头,是一串字符串,相当于浏览器的身份证号,我们在利用python发送 [……] 继续阅读»»»
python爬虫之多线程threading、多进程程multiprocessing、协程aiohttp 批量下载图片 一、单线程常规下载 常规单线程执行脚本爬取壁纸图片,只爬取一页的图片。 执行结果: 结果,第一页24张图片,就下载差不多8分钟,排除网络等因素,还没有手动下载快。 二、多线程下载 上面的有两个循环,第一个是页面的循环,一页一页的加载,每页在单独循坏单独下载图片。 所以有两个等待时间,第一个就是等待第一页下载完成,才会到第二页。第二个等待就是每页图片一张下载完才下载第二张。 综上,优化两点:第一点, [……] 继续阅读»»»
python爬虫练习selenium+BeautifulSoup库,爬取b站搜索内容并保存excel 一、简介 前面文章已经介绍了selenium库使用,及浏览器提取信息相关方法。参考:python爬虫之selenium库 现在目标要求,用爬虫通过浏览器,搜索关键词,将搜索到的视频信息存储在excel表中。 二、创建excel表格,以及chrome驱动 三、创建定义搜索函数 里面有button_next 为跳转下一页的功能,之所有不用By.CLASS_NAME定位。看html代码可知 class名 [……] 继续阅读»»»